Mixture of Expert Model for Code Generation
Introduction
The exponential growth in software development demands has created an urgent need for efficient, accessible code generation solutions. While large language models have shown promising results in code generation, their computational requirements often restrict access to major corporations with substantial resources. Our project addresses this critical challenge by implementing a Mixture-of-Experts (MoE) framework that makes advanced code generation capabilities accessible to a broader developer community.
Project Objective
We aim to develop a cost-effective, high-performance code generation system using the MoE framework, capable of generating quality code across multiple programming languages while maintaining efficiency and accessibility.
Innovation and Social Impact
Our approach democratizes access to advanced AI-powered code generation by:
- Reducing computational requirements by 50% compared to traditional models
- Maintaining high accuracy through specialized language experts
- Making enterprise-level code generation accessible to individual developers and smaller organizations
- Social Value: By lowering the barrier to entry, we empower a diverse range of developers, fostering innovation and inclusivity in the tech community
Methodology
Base Architecture
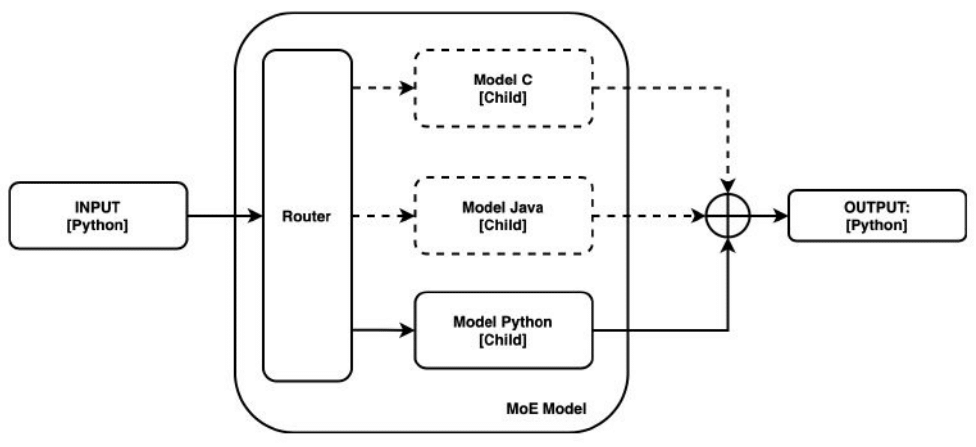
We built our system on the Mistral-7B model, implementing specialized experts for Python, Java, JavaScript, and C++. The architecture employs a sophisticated gating mechanism that routes queries to the most appropriate language expert.
Implementation Details
- Dataset: 10,000 high-quality text-to-code pairs per language
- Training Infrastructure: AWS A10G GPU with 26GB RAM
- Fine-tuning Duration: 48-72 hours per language expert
- Evaluation Metric: CodeBLEU benchmark
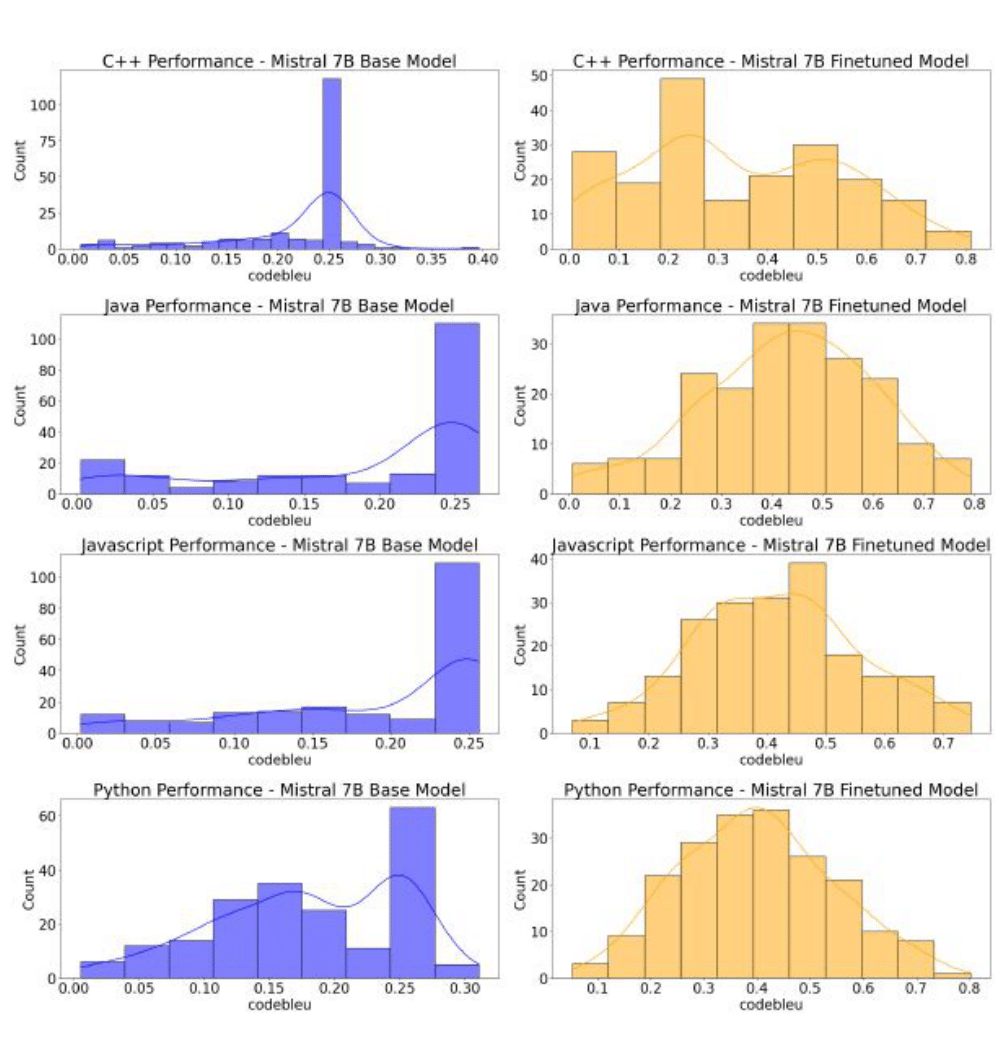
Results
Our MoE implementation achieved significant improvements:
| Language | Baseline Score | Fine-tuned Score |
|---|---|---|
| Python | 0.1800 | 0.4000 |
| Java | 0.1860 | 0.4287 |
| JavaScript | 0.1909 | 0.4182 |
| C++ | 0.2170 | 0.3340 |
Personal Contribution
As part of the four-member team, my primary responsibilities included:
- Implementing the gating mechanism for expert selection
- Fine-tuning individual language experts
- Conducting performance evaluations using CodeBLEU
- Documenting methodology and results
- Role: I played a crucial role in ensuring the system’s efficiency and accuracy, directly contributing to the project’s success and its positive social impact.
Discussions
The project has laid groundwork for several promising extensions:
- Expanding language support
- Implementing attention-layer expert selection
- Enhancing the gating mechanism for better expert routing
- Incorporating human feedback through RLHF
This project demonstrates that complex AI capabilities can be made accessible without compromising performance, potentially transforming how developers across the resource spectrum approach code generation.